初級7
AI・テクノロジー
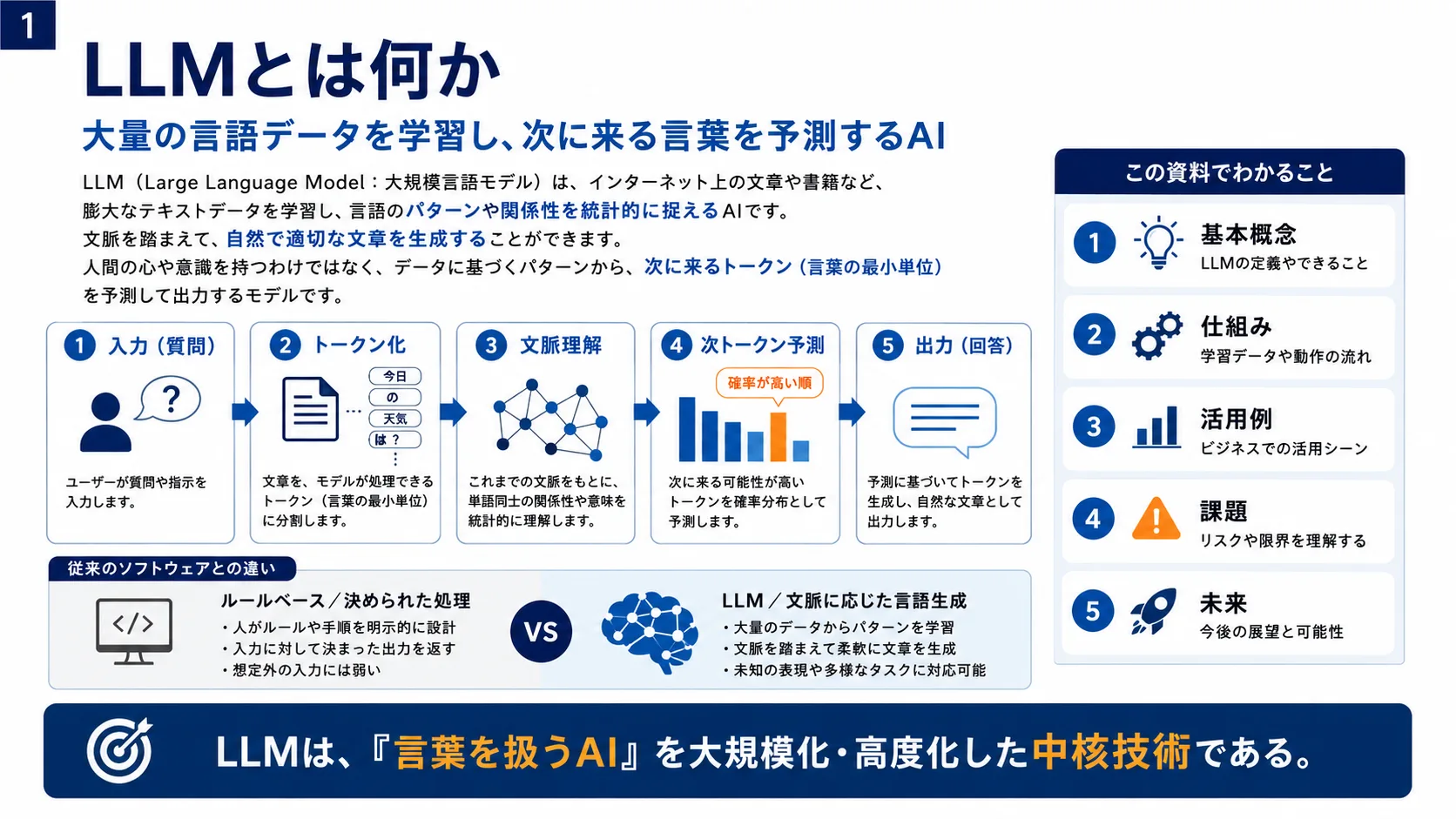
LLM(大規模言語モデル)
編集部
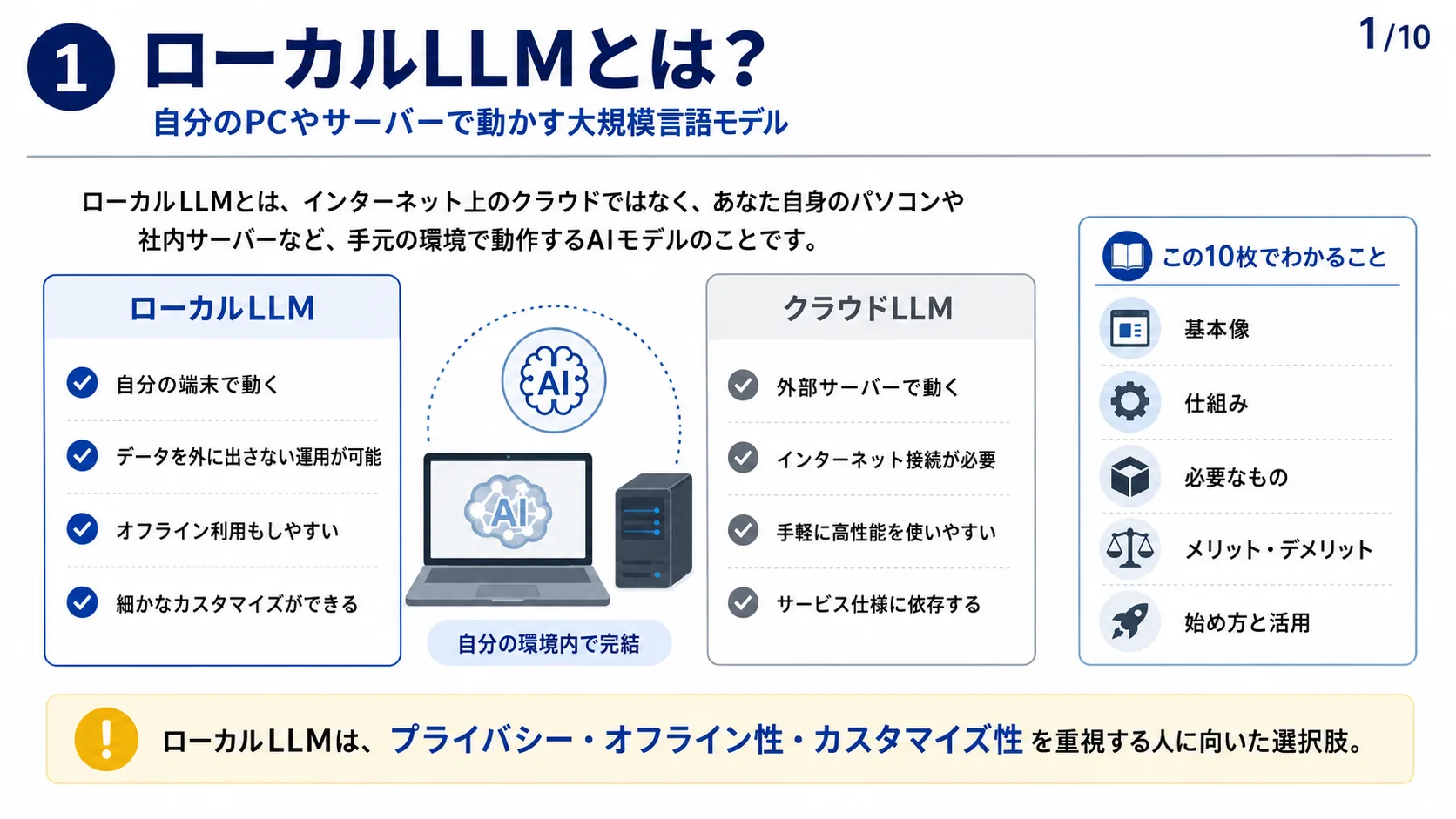
ローカルLLMとは、インターネット上のクラウドではなく、あなた自身のパソコンや社内サーバーなど、手元の環境で動作するAIモデルのことです。自分の端末で動き、データを外に出さない運用が可能で、オフライン利用もしやすく、細かなカスタマイズができるのが特徴です。クラウドLLMは外部サーバーで動きインターネット接続が必要ですが、手軽に高性能を使えるかわりにサービス仕様に依存します。この10枚では、ローカルLLMの仕組み・必要なもの・メリットとデメリット・始め方・活用例をお伝えします。
ローカルLLMはモデルを自分の端末で読み込み、入力を受けて推論する仕組みです。まず事前にダウンロードした.gguf形式などのモデルファイルを端末に保存しておきます。次に推論ソフト(OllamaやLM Studioなど)がモデルファイルを読み込みます。ユーザーがテキストで質問や指示(プロンプト)を入力すると、端末のCPUやGPUでモデルが推論処理を行い、生成された回答テキストがユーザーに返されます。データのやり取りはすべて手元の環境で完結します。
ローカルLLMを導入する前に、いくつかの基本要素をそろえる必要があります。まずハードウェア(CPU・GPU・メモリ)で、推論の速度や品質は搭載するGPUの種類と数・大きさで決まります。メモリの目安は小さいモデルで4GB以上、大きめのモデルでは16GB以上が推奨されます。次にモデル(Llama、Gemma、Mistralなど)は用途や出力品質に応じて選び、OllamaやHugging Faceなどから入手できます。また推論ソフト(OllamaやLM Studio)でモデルを実行します。
代表的なオープンモデルを用途別に紹介します。Meta社のLlama系はバランスが良い汎用モデル群で、3B/7B/13B/70Bのサイズがあり、汎用チャット・要約・翻訳・コード補完など幅広く対応します。GoogleのGemma系は高品質・高効率モデルで2B〜220Bのサイズがあり、文書作成・翻訳・研究用途に適しています。またフランス発のMistral系は軽量・高性能モデル群として知られており、7B/8Bサイズが代表的です。モデルの選択は用途・スペック・必要な品質のバランスで決めましょう。
ローカルLLMには、クラウド利用と比べたいくつかの強みがあります。まずプライバシー保護として、データを社外に送信しないため機密情報や個人情報を含む処理も安全に行えます。次にオフライン利用が可能で、インターネット接続がなくても動作します。またカスタマイズ性が高く、ファインチューニングを行ってモデルの挙動や応答スタイルを調整できます。さらに長期的なコストの観点から、初期費用はかかるものの月額費用がかからず大量利用に対してコスト効率が高くなる場合があります。
ローカルLLMの導入にはいくつかのハードルもあります。まず初期費用がかかる点で、高性能なGPUや大容量メモリのPC・サーバーが必要です。次にセットアップの手間があり、環境構築やドライバ設定、依存ライブラリのインストールなど初期設定に時間がかかります。また性能が環境に依存するため、PCのスペックやメモリ量で応答速度・品質が変わります。さらにモデル更新と保守が必要で、モデルやツールの更新、互換性の確認、セキュリティ対応も継続して行う必要があります。
まず用途を決めることが大切です。文章作成・要約・翻訳・プログラミング支援など、どんなことに使いたいかを明確にしましょう。次に推論ソフトを選びます。コマンドラインで手軽に使えるOllamaや、GUIで操作できるLM Studioなどが代表的です。その後使いたいモデルをダウンロードし、最後に実際に使ってみながらプロンプトを工夫して精度を確認します。初めはシンプルな構成で試し、慣れてきたらモデルを切り替えたり設定を変えたりして最適化していきましょう。
ローカルLLMは個人利用から社内業務まで幅広く活用できます。長文レポートや資料を要約して重要ポイントを素早く把握する文書要約、コードの生成・補完・エラー解説を支援するプログラミング補助、社内ルールや制度への質問に回答できる社内FAQなどに活用できます。また企画や改善案のブレインストーミングを支援するアイデア出しや、インターネットが使えない環境での対話支援にも対応します。機密情報を扱う業務や特定のカスタマイズが必要な用途に特に向いています。
快適に使うための実践ポイントを紹介します。まずGPUを活用すると処理速度と安定性が大幅に向上します。次に十分なRAMを確保することが重要で、不足すると動作が不安定になりやすいため余裕をもって用意しましょう。また高速SSDを使うとモデルの読み込み時間が短縮されます。さらに量子化モデルを選ぶことでモデルサイズを抑えつつある程度の品質を維持できます。用途に合ったモデルサイズを選ぶことも大切で、必要以上に大きなモデルを使うとスペックに見合わない負荷がかかります。
今回はローカルLLMについてお伝えしました。ローカルLLMはインターネット通信に依存せず自分のPCやサーバーで完結して利用でき、データが外部送信されないためプライバシーに強いという特長があります。一方で環境構築やモデル選定にある程度の技術的知識が必要であり、用途に合ったモデルを選ぶことが重要です。クラウドLLMとうまく使い分けながら、目的に合った形で活用することをおすすめします。