初級14
AIツール・LLMプラットフォーム
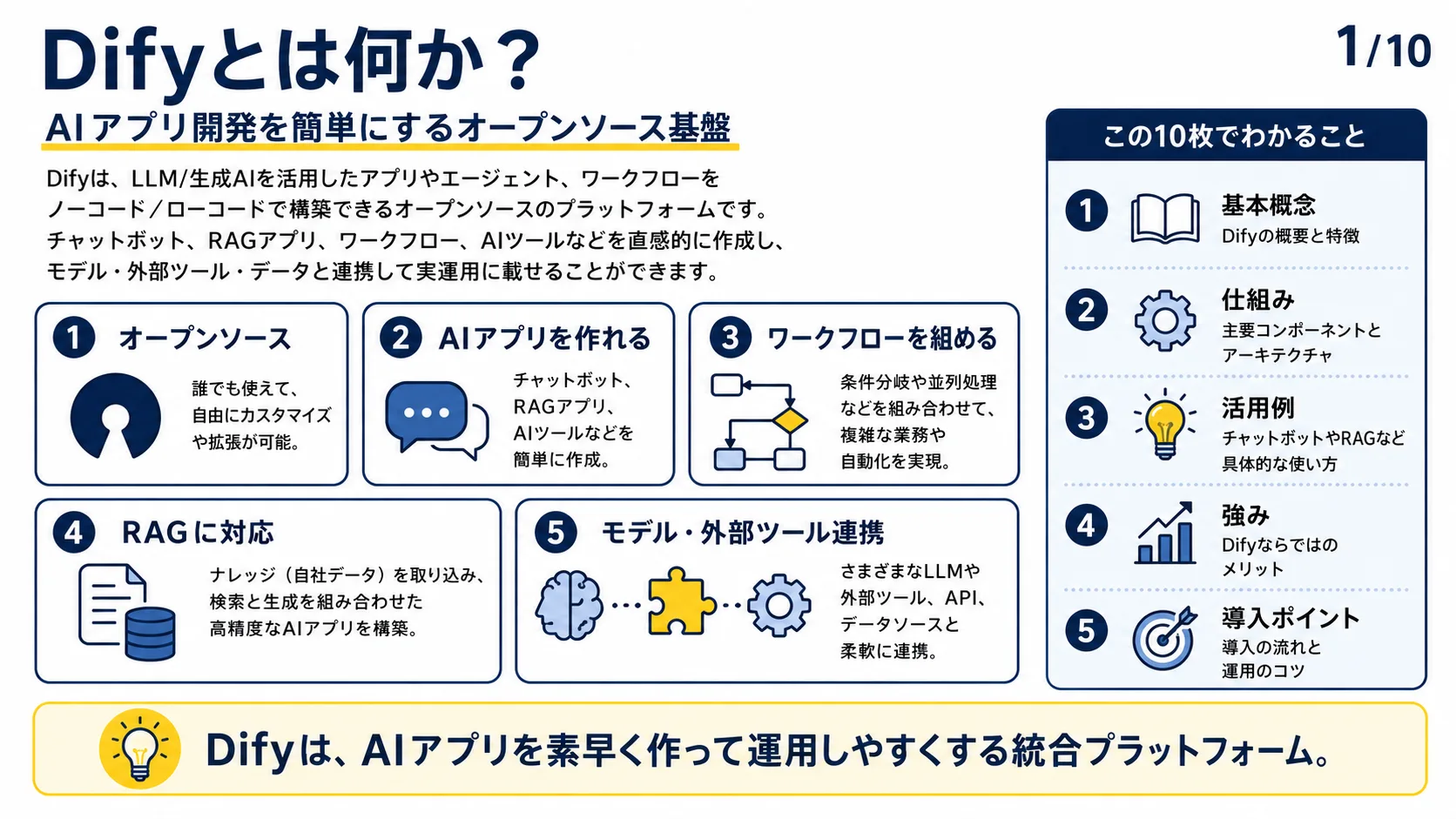
Difyとは何か?
編集部
ChatGPTを生んだLLM(大規模言語モデル)の仕組みを、トークン予測・Transformer・事前学習から丁寧に解説。ビジネス活用・RAG・AIエージェントの最前線から、ハルシネーションやバイアスといったリスクまで、AI時代を生き抜く教養として整理する。
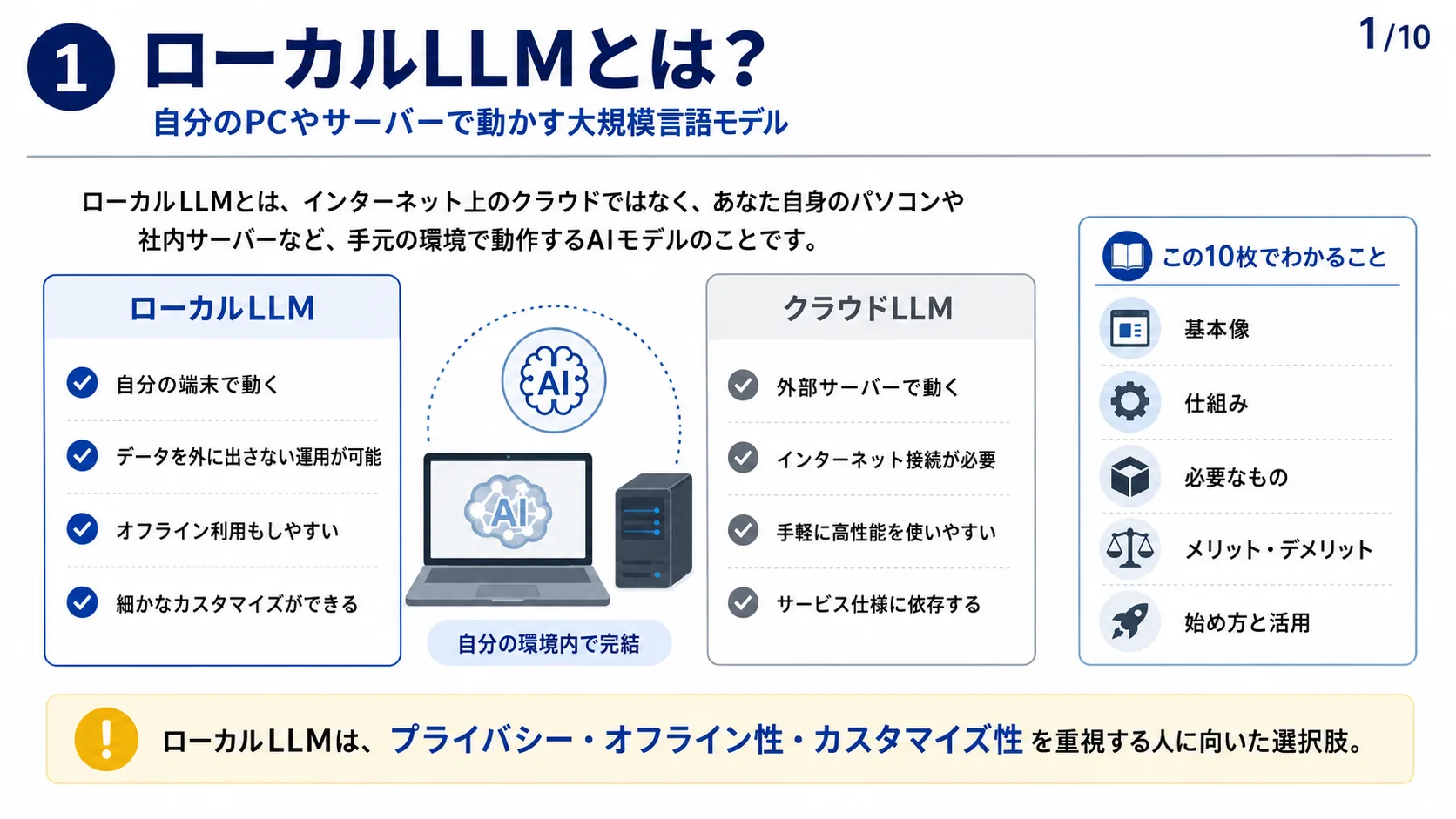
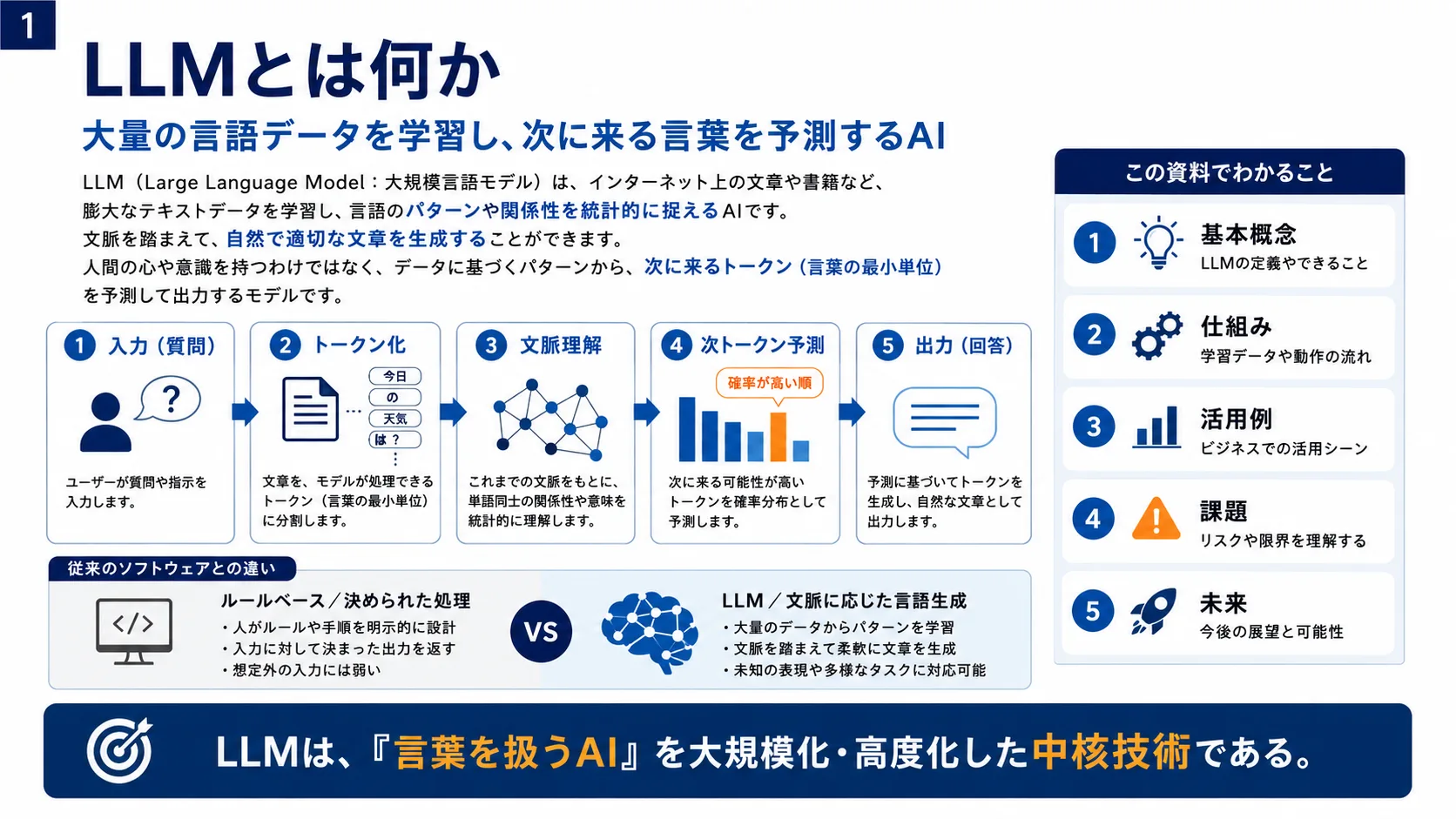
LLM(Large Language Model)は、インターネット上の文章や書籍など、膨大なテキストデータを学習し、言語のパターンや関係性を統計的に記述するAIです。ユーザーが質問や指示を入力すると、文章をトークンに分割し、文脈を踏まえて次のトークンを予測することで自然な文章を生成します。従来のルールベースのソフトウェアとは異なり、多様な課題に対応できる汎用性を持ちます。LLMは「言葉を扱うAI」を大規模化・高度化した中核技術です。
大量のデータ、強力な計算資源、優れたアルゴリズム、そして使いやすいインターフェースが組み合わさって、AIが「誰でも使えるもの」へと進化しました。自然言語で操作できること、汎用性が高いこと、導入コストが下がったこと、性能の向上、そして新サービスの創出基盤となることが注目される理由です。LLMブームは、技術の偶然ではなく「条件が整った結果」といえます。
LLMは入力された文章をトークンに分割し、数値ベクトルに変換します。Transformerと呼ばれる仕組みが、Attention(注意機構)によって文脈の重要な部分に注目し、「次に来る確率の高い単語」を予測することで自然な文章が生成されます。人間のような意味の理解とは異なり、大量のテキストから統計的なパターンを学習した確率的な推測です。LLMの本質は「意味を計算しているように見える高精度な次語予測装置」といえます。
LLMの学習は段階的に進みます。まず大量のテキストから言語パターンを習得する事前学習、次に特定のスキルや分野に向けて微調整する指示調整、そして人間の評価をもとに品質改善を行う強化学習というプロセスを経ます。利用フェーズでは原則として使用中に自動学習することはなく、学習済みデータをもとにリアルタイムで応答します。LLMの性能はモデルの大きさだけでなく、学習工程の設計によって大きく左右されます。
LLMは文章作成・要約・翻訳・質問回答・コーディング支援・アイデア発想など幅広い知的作業を支援します。自然言語で操作できるため専門知識がなくても活用でき、文章を扱うあらゆる仕事に応用できます。ドラフトや試案を素早く大量に出せるため、0から1への発想や1から10への精練を加速させます。LLMは「答えを完全自動で出す機能」というより、「知的作業の下書きと加速装置」です。
LLMは営業・カスタマーサポート・開発・バックオフィスなど、あらゆる業務で「考える・文章をつくる・調べる」のサポートをします。時間短縮・品質の平準化・担当者の負荷軽減・ナレッジ蓄積・多言語対応といったメリットがあります。ただし丸投げは禁物で、社外情報や個人情報の取り扱いには注意が必要です。LLMの価値は単なる自動化よりも「人の判断を強くすること」にあります。
LLM単体では学習データの範囲にとどまります。RAG(外部文書を検索して回答する手法)を使うことで最新情報や社内資料に対応でき、ツール利用でAPI呼び出しや計算ができ、エージェント化で複数ステップのタスクを自律処理できます。これらを組み合わせることでハルシネーションのリスク低減、正確さの向上、繰り返し作業の自動化が実現します。LLM単体より「情報源・道具・手順」と組み合わせたときに本当の力が出ます。
LLMには事実と異なる内容をもっともらしく生成するハルシネーション、学習データの偏りによるバイアス、情報漏えいのリスク、著作権・法務上の問題、そして過信による思考停止といったリスクがあります。安全に使うためには、AIの出力を鵜呑みにせず一次情報を確認すること、個人情報を入力しないこと、医療・法律・財務などの専門判断は人が行うことが大切です。LLM活用で大切なのは「使わないこと」ではなく「正しく使うこと」です。
LLMで成果を出すには、モデル選定より「運用設計」が重要です。目的設定・対象業務選定・プロンプト設計・評価方法・セキュリティ・ガバナンス・人の役割設計という6つのポイントを押さえることが成功の鍵です。「とりあえず導入」「使い道が曖昧」「ルールなし」「評価なし」といった失敗パターンを避け、スモールスタートで効果を出しながら継続的に改善していくことが重要です。LLM導入の成否は「どのモデルか」より「どう業務に埋め込むか」で決まります。
今回は、LLMの概要から仕組み、活用、リスク、導入ポイントまでをお伝えしました。今後はマルチモーダル化・低コスト化・専門モデル化・オンデバイス化・AIエージェント化が進み、AIはより身近な「共同作業者」になっていきます。人の役割はより創造的・判断的な領域へと変化し、AIを使いこなす個人や組織が競争力を持つようになるでしょう。LLMは「人間の代替」ではなく「人間の知的能力を拡張する基盤」として捉えることが重要です。