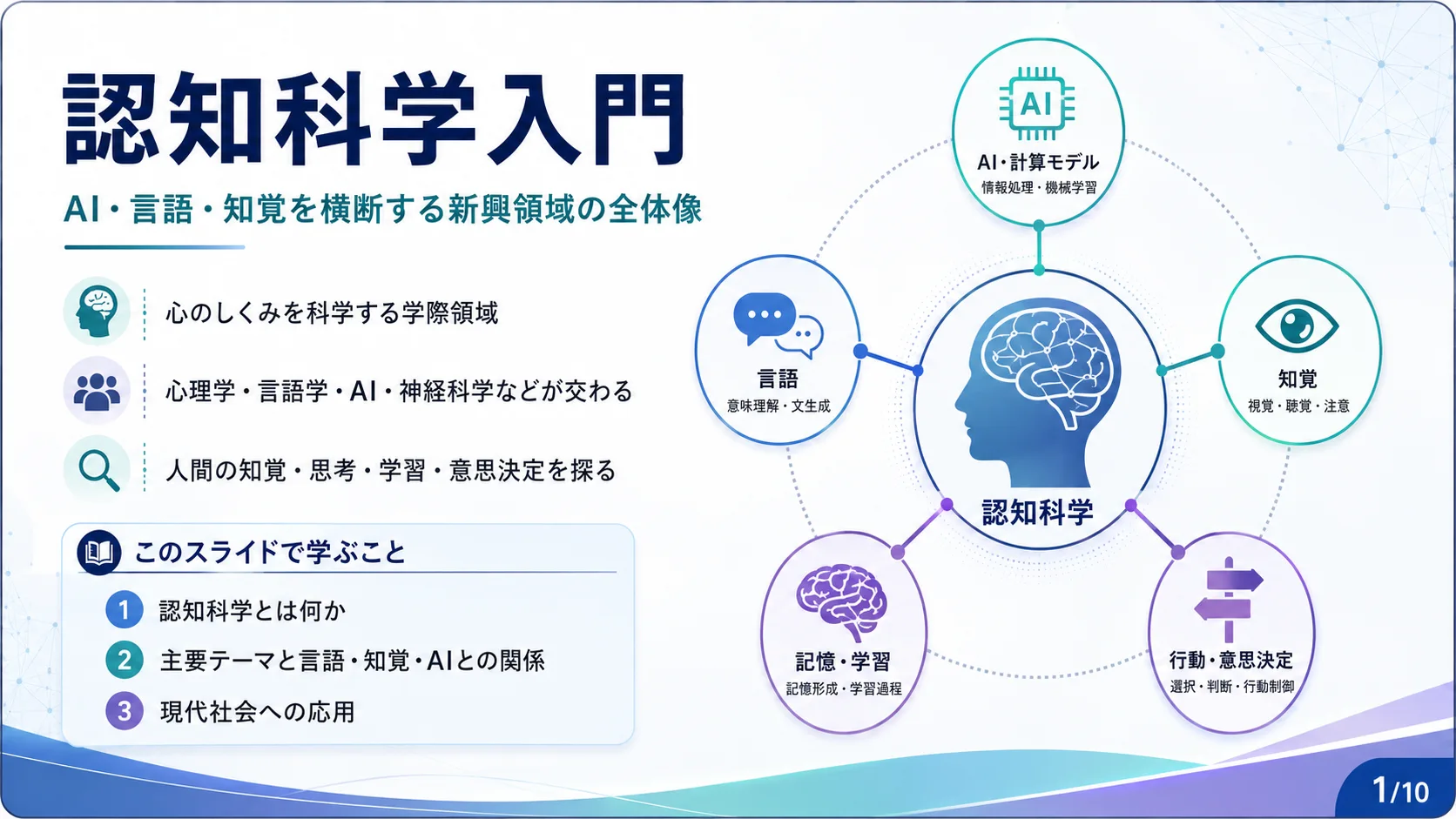
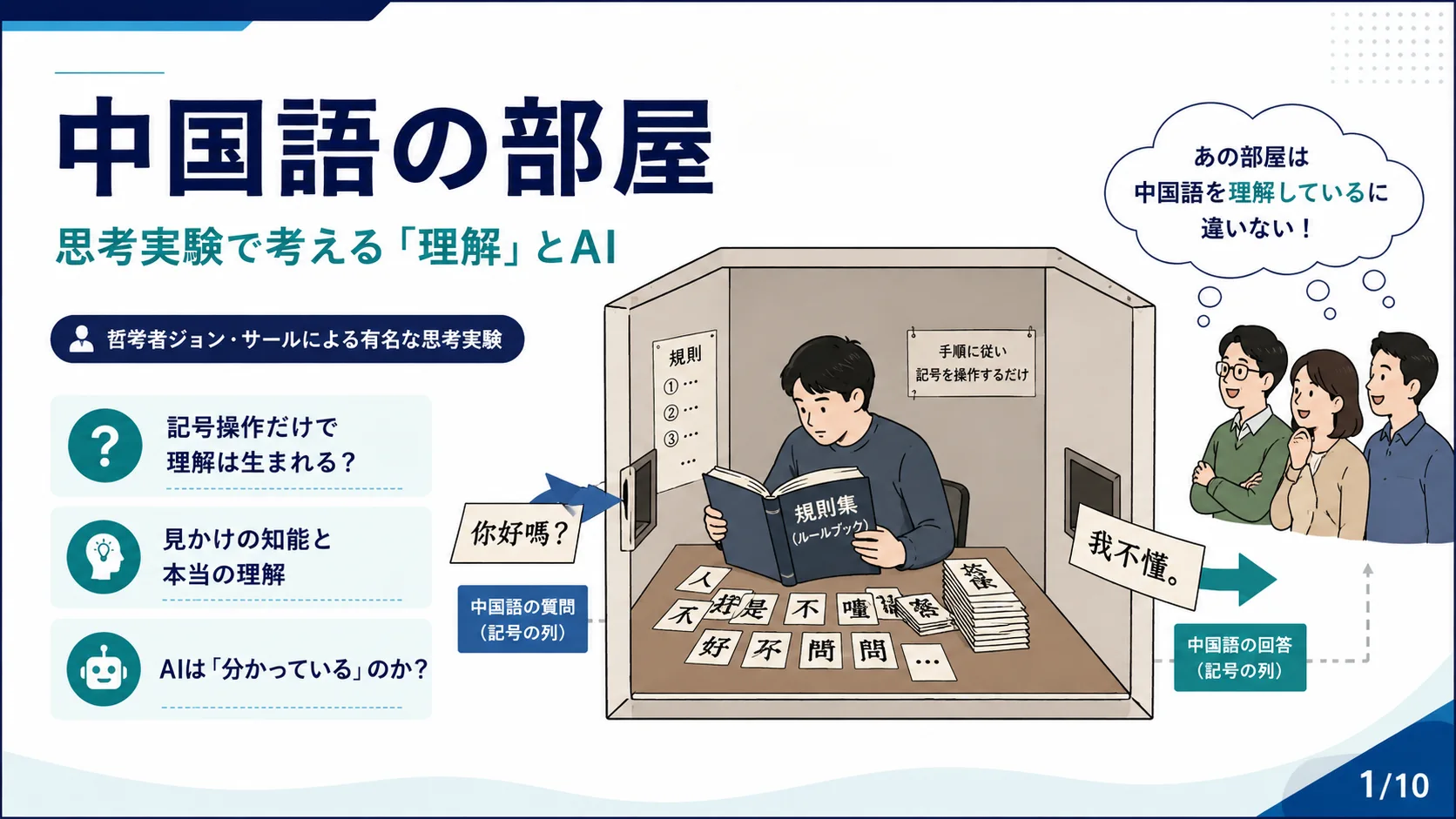
初級4
AI・計算機科学
チューリングテストとは何か
編集部
機械学習とは、データからパターンを学習し予測や判断を自動的に改善するAIの中核技術です。教師あり学習・教師なし学習・強化学習の3手法を基盤に、深層学習が音声認識・画像認識・自然言語処理などで飛躍的な成果を上げています。このスライドでは、機械学習の基本概念・学習の仕組み・代表的な応用例を解説します。
AI(人工知能)は人間のように考えたり判断したりする処理を実現する幅広い技術の総称です。機械学習はAIの一分野で、データからパターンを学習し、プログラムされていなくても予測や判断を向上させる手法です。深層学習は機械学習の一種で、多層のニューラルネットワークを用いてデータの特徴を自動的に抽出・学習する手法で、音声認識・画像認識・自然言語処理などに特に強みを発揮します。AIが最も広い概念で、機械学習はその一部、深層学習はさらにその一部です。
機械学習には目的に応じた三つの代表的な学習方法があります。教師あり学習はラベル付きのデータを使い入力と正しい出力の関係を学習する手法で、スパム検出・住宅価格推定・画像分類などに使われます。教師なし学習はラベルのないデータからデータの構造やパターンを見つける手法で、顧客のクラスタリングや異常検知などに活用されます。強化学習は報酬を受け取りながら試行錯誤で最適な行動を学習する手法で、ゲームAIやロボット制御に使われます。
教師あり学習はデータ収集・前処理・学習データとテストデータへの分割・モデル学習・評価・改善というステップで進みます。データは「特徴量(入力)」と「ラベル(正解)」の形で構成されます。たとえば住所・面積・築年数が特徴量で、スパム/非スパムがラベルです。代表タスクとして、カテゴリを予測する「分類」(メールのスパム判定など)と、連続値を予測する「回帰」(住宅価格の予測など)があります。入力と正解の組を使って、未知データにも適用できる予測モデルを育てていきます。
機械学習には目的に応じた多様なアルゴリズムがあります。予測・分類でよく使われる手法として、連続値を予測する線形回帰、確率を出力し分類する ロジスティック回帰、条件分岐で予測する決定木、決定木の組み合わせで高精度なランダムフォレストがあります。データの構造を見つける手法にはk-meansや主成分分析(PCA)があります。また高度な手法として、サポートベクターマシン、ニューラルネットワーク、勾配ブースティングがあります。アルゴリズムにはそれぞれ強みと弱みがあり、データの性質と目的に合わせて選ぶことが重要です。
モデルの性能を確認するためにデータを訓練・検証・テストに分けます。評価指標として、正しく予測できた割合を示す正確率(Accuracy)、陽性と予測したうちの正解の割合である適合率(Precision)、実際の陽性のうち正しく予測できた割合の再現率(Recall)、その調和平均のF1スコアなどがあります。目的によって重視する指標が変わり、たとえば医療のがん診断ではRecallを、スパムフィルタではPrecisionを重視します。未知データにどれだけうまく対応できるかを適切な指標で確認することが重要です。
過学習とは、モデルが訓練データの細かいノイズや偶然のパターンに過剰に適応し、未知データへの性能が低下する現象です。過去問をそのまま暗記して本番の問題を解けなくなるようなイメージです。訓練データでの誤りは低いのに検証データでの誤りが上がり始めるグラフで見分けられます。対策としては、データを増やす、特徴量を絞る、モデルを単純化する、正規化(L1/L2)を行う、交差検証を実施するなどがあります。本当によいモデルとは、訓練データだけでなく未知のデータにも安定して適用できるモデルです。
機械学習の性能はアルゴリズムだけでなく、データ前処理と特徴量設計の質に大きく左右されます。前処理の基本として、欠損値の補完や削除、外れ値の特定と除外、カテゴリ変数の数値化などがあります。特徴量はモデルが学習に使用する入力データで、年齢・購入履歴・ページ滞在時間などがその例です。特徴量エンジニアリングとして、特徴量の変換・選択・次元削減・エンコーディングなどを行います。データリークへの注意、クラス不均衡への対処、ドメイン知識の活用も重要です。
機械学習は日常から産業の現場まで幅広く活用されています。身近な例として、過去の閲覧データからコンテンツを提案するレコメンドシステム、迷惑メールを自動分類するスパムフィルタリング、検索結果の最適化、音声アシスタントがあります。産業での活用として、製造・在庫の効率化のための需要予測、設備の異常検知と予知保全、医療画像からの疾患自動指摘などがあります。業務効率の向上・サービス品質の改善・リスクの低減・意思決定のサポートに大きな価値を生み出しています。
今回は機械学習についてお伝えしました。機械学習はデータからパターンを学び未来の予測や意思決定を支援する技術で、教師あり・教師なし・強化学習という三つの代表的な学習方法があります。アルゴリズムは目的やデータに応じて適切に選ぶことが重要で、評価を通じて性能を確認し汎化(一般化)を実現することが鍵となります。また前処理と特徴量の設計が性能を大きく左右します。機械学習を理解することはデータを活かして未来を読み解く能力を身に付ける第一歩です。